In the previous posts in this series, we’ve seen some examples of long running processes, how to model them and where to store the state. But building distributed systems is hard. And if we are aware of the fallacies of distributed systems, then we know that things fail all the time. So how can we ensure that our long running process doesn’t get into an inconsistent state if something fails along the way?
Let’s see some strategies for dealing with failure in the Shipping service. First, let’s have another looks at the shipping policy defined in the previous post:
- First, attempt to ship with Fan Courier.
- If cannot ship with Fan Courier, attempt to ship with Urgent Cargus.
- If we did not receive a response from Fan Courier within the agreed SLA, cancel the Fan Courier shipment and attempt to ship with Urgent Cargus.
- If we cannot ship with Urgent Cargus or did not receive a response within the agreed SLA, notify the IT department.
Retries
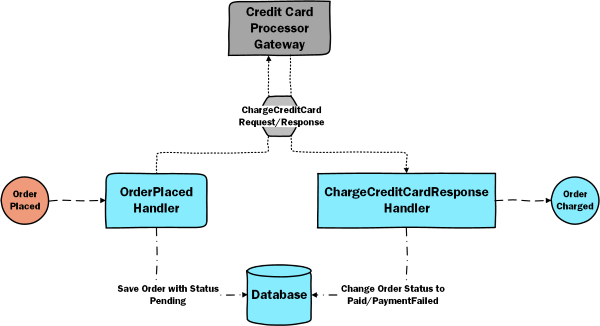
The Fan Courier Gateway handles the ShipWithFanCourierRequest message and calls the Fan Courier HTTP API. What happens if we get an Internal Server Error?

The simplest thing we could do would be to retry. What if it still fails? Then we can wait a bit, then retry again. For example, we can retry after 10 seconds. If it still fails, retry after 20 and so on. These Delayed Retries are a very useful strategy for getting over transient errors (like a deadlock in the database). We could even increase the time between retries exponentially, using an exponential backoff strategy.
Idempotent Receiver
One thing that you need to be mindful when retrying is message idempotency. What happens if we get an HTTP timeout when calling the Fan Courier HTTP API, but our shipment request was actually processed successfully, we just didn’t get the response back? When we retry, we don’t want to send a new shipment. This is why the Fan Courier Gateway needs to be an Idempotent Receiver. This means that it doesn’t matter if it processes the same message only once or 5 times, the result will always be the same: a single shipment request. There are several ways of implementing an idempotent receiver, but these are outside of the scope of this article.
Timeouts
But what if the Fan Courier API is down? Retrying won’t help. So what can we do? When we send the ShipWithFanCourierRequest we can also raise a timeout within 30 minutes (at line 8). When we receive the timeout message (line 13) we can take some mitigating actions. The shipping policy states that we’d like to attempt to ship with Urgent Cargus. In order to do that, we’ll want to first cancel the Fan Courier shipment (line 17). This is what’s called a compensating transaction because it will undo the effects of the initial transaction. Then, we’ll send a ShipWithUrgentCargusRequest.
public Task Handle(ShipOrder message, IMessageHandlerContext context)
{
Data.OrderId = message.OrderId;
Data.Status = ShippingStatus.ShippingWithFanCourier;
context.Send(new ShipWithFanCourierRequest { CorrelationId = Data.OrderId });
RequestTimeout(context, shipmentSla, new DidNotReceiveAResponseFromFanCourierTimeout());
return Task.CompletedTask;
}
public Task Timeout(DidNotReceiveAResponseFromFanCourierTimeout state, IMessageHandlerContext context)
{
if (Data.Status == ShippingStatus.ShippingWithFanCourier)
{
context.Send(new CancelFanCourierShipping { CorrelationId = Data.OrderId });
ShipWithUrgentCargus(context);
}
return Task.CompletedTask;
}
Dead Letter Channel
What happens if the UrgentCargus API is down too? We can send the message to an error queue. This is an implementation of the Dead Letter Channel pattern. A message arriving in the error queue can trigger an alert and the support team can decide what to do. And this is important: you don’t need to automate all edge cases in your business process. What’s the point in spending a sprint to automate this case, if it only happens once every two years? The costs will definitely outweigh the benefits. Instead, we can define a manual business process for handling these edge cases.
In our example, if Bob from IT sees a message in the error queue, he can inspect it and see that it failed with a CannotShipOrderException. In this case he can notify the Shipping department and they can use another shipment provider. But all of this happens outside of the system, so the system is less complex and easier to build.
Saga
Another failure management pattern is the Saga pattern. Let’s see an example.
Requirement
The Product Owner would like to introduce a new feature – the ability to ship high volume orders. But there’s a catch: high volume orders are too large to ship in a single shipment. We need to split them in batches. But, we only want to ship complete orders. This means that if we cannot ship one batch, we don’t want to ship any batch.
The Saga pattern advocates splitting the big transaction (ship all batches) into smaller transactions (one per batch). But since these transactions are not isolated, we need to be able to compensate them:

The ShipHighVolumeOrderSaga in the sample code base shows how to use the Saga pattern to implement this feature.
Benefits
Avoids Distributed Locks
By using the Saga pattern you avoid using distributed locks and two-phase commits. This means that you avoid the single point of failure – the distributed transaction coordinator – and it’s more performant.
Atomic, Consistent, Durable
If you implement this pattern correctly, you can get Atomicity, Consistency and Durability guarantees.
Drawbacks
Lack of Isolation
The lack of isolation can cause anomalies. If between T1 and T2 you get a T4, you need to decide what to do. You can easily get into an inconsistent state.
Complex
Handling these cases and all the different orders that messages can arrive can introduce complexity.
If you want to learn more about the saga pattern, I also recommend this article by Clemens Vasters and this this presentation by Caitie McCaffrey.
Conclusion
In this article we’ve seen some patterns for handling failures in long running processes. We started with the easier ones: retries and delayed retries, timeouts, compensating transactions and dead letter channels. Then we’ve briefly covered a more complex pattern – the saga pattern. I keep the saga pattern at the bottom of my toolbox and I avoid it if possible. Many times, you can get around it by using simpler patterns.
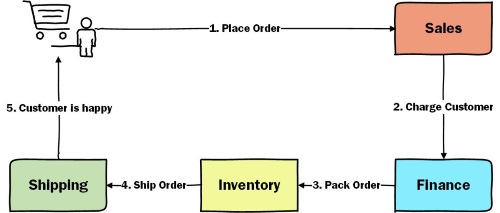
In this article series we’ve seen how we can use different patterns to implement long running processes. To showcase the patterns, we’ve used a sample eCommerce product that looks like this:

If you want to have a look at the code, you can find it on my github account.