In this microservices era, many teams are building messaging solutions. What starts as a simple solution with 5 deployment units can quickly grow to tens or even hundreds. I have worked on such a solution for several years and experienced both the advantages and disadvantages of a Service-Oriented Architecture. We used NServiceBus (part of Particular’s Service Platform).
The solution started out simple, but, as the number of features grew, so did the complexity. With tens of message endpoints, it was hard to see both the big picture and the details. For the big picture, we could rely on some manually created diagrams (e.g. a Context View in Simon Brown’s C4 model). But things got trickier when we wanted to understand the details. When I talk about details, I mean answers to specific questions. For example:
What messages does endpoint X send/receive?
What endpoints are coupled to the X endpoint?
What messages are part of the Y business flow?
What messages is service Z sending?
What messages trigger message W to be sent?
Show me the entire message flow that starts with message W.
While I was thinking about this, I saw this interesting tweet from Jack Kleeman that showed the communication paths between microservices at Monzo:
Now, the system I worked on was nowhere near this complex, but it made me wonder: how can you answer the questions above when working on such a system? In this blog post we’ll explore some options. To keep things simple, in this blog post we’ll use a sample eCommerce solution (that I’ve also used in my article series about Designing long-running processes in distributed systems).
In the previous posts in this series, we’ve seen some examples of long running processes, how to model them and where to store the state. But building distributed systems is hard. And if we are aware of the fallacies of distributed systems, then we know that things fail all the time. So how can we ensure that our long running process doesn’t get into an inconsistent state if something fails along the way?
Let’s see some strategies for dealing with failure in the Shipping service. First, let’s have another looks at the shipping policy defined in the previous post:
First, attempt to ship with Fan Courier.
If cannot ship with Fan Courier, attempt to ship with Urgent Cargus.
If we did not receive a response from Fan Courier within the agreed SLA, cancel the Fan Courier shipment and attempt to ship with Urgent Cargus.
If we cannot ship with Urgent Cargus or did not receive a response within the agreed SLA, notify the IT department.
Retries
The Fan Courier Gateway handles the ShipWithFanCourierRequest message and calls the Fan Courier HTTP API. What happens if we get an Internal Server Error?
The simplest thing we could do would be to retry. What if it still fails? Then we can wait a bit, then retry again. For example, we can retry after 10 seconds. If it still fails, retry after 20 and so on. These Delayed Retries are a very useful strategy for getting over transient errors (like a deadlock in the database). We could even increase the time between retries exponentially, using an exponential backoff strategy.
Idempotent Receiver
One thing that you need to be mindful when retrying is message idempotency. What happens if we get an HTTP timeout when calling the Fan Courier HTTP API, but our shipment request was actually processed successfully, we just didn’t get the response back? When we retry, we don’t want to send a new shipment. This is why the Fan Courier Gateway needs to be an Idempotent Receiver. This means that it doesn’t matter if it processes the same message only once or 5 times, the result will always be the same: a single shipment request. There are several ways of implementing an idempotent receiver, but these are outside of the scope of this article.
Timeouts
But what if the Fan Courier API is down? Retrying won’t help. So what can we do? When we send the ShipWithFanCourierRequest we can also raise a timeout within 30 minutes (at line 8). When we receive the timeout message (line 13) we can take some mitigating actions. The shipping policy states that we’d like to attempt to ship with Urgent Cargus. In order to do that, we’ll want to first cancel the Fan Courier shipment (line 17). This is what’s called a compensating transaction because it will undo the effects of the initial transaction. Then, we’ll send a ShipWithUrgentCargusRequest.
What happens if the UrgentCargus API is down too? We can send the message to an error queue. This is an implementation of the Dead Letter Channel pattern. A message arriving in the error queue can trigger an alert and the support team can decide what to do. And this is important: you don’t need to automate all edge cases in your business process. What’s the point in spending a sprint to automate this case, if it only happens once every two years? The costs will definitely outweigh the benefits. Instead, we can define a manual business process for handling these edge cases.
In our example, if Bob from IT sees a message in the error queue, he can inspect it and see that it failed with a CannotShipOrderException. In this case he can notify the Shipping department and they can use another shipment provider. But all of this happens outside of the system, so the system is less complex and easier to build.
Saga
Another failure management pattern is the Saga pattern. Let’s see an example.
Requirement
The Product Owner would like to introduce a new feature – the ability to ship high volume orders. But there’s a catch: high volume orders are too large to ship in a single shipment. We need to split them in batches. But, we only want to ship complete orders. This means that if we cannot ship one batch, we don’t want to ship any batch.
The Saga pattern advocates splitting the big transaction (ship all batches) into smaller transactions (one per batch). But since these transactions are not isolated, we need to be able to compensate them:
The ShipHighVolumeOrderSaga in the sample code base shows how to use the Saga pattern to implement this feature.
Benefits
Avoids Distributed Locks
By using the Saga pattern you avoid using distributed locks and two-phase commits. This means that you avoid the single point of failure – the distributed transaction coordinator – and it’s more performant.
Atomic, Consistent, Durable
If you implement this pattern correctly, you can get Atomicity, Consistency and Durability guarantees.
Drawbacks
Lack of Isolation
The lack of isolation can cause anomalies. If between T1 and T2 you get a T4, you need to decide what to do. You can easily get into an inconsistent state.
Complex
Handling these cases and all the different orders that messages can arrive can introduce complexity.
In this article we’ve seen some patterns for handling failures in long running processes. We started with the easier ones: retries and delayed retries, timeouts, compensating transactions and dead letter channels. Then we’ve briefly covered a more complex pattern – the saga pattern. I keep the saga pattern at the bottom of my toolbox and I avoid it if possible. Many times, you can get around it by using simpler patterns.
In this article series we’ve seen how we can use different patterns to implement long running processes. To showcase the patterns, we’ve used a sample eCommerce product that looks like this:
If you want to have a look at the code, you can find it on my github account.
Testing is an important part of building a product right. Continuous Delivery makes that more explicit by building quality in. In this blog post we’ll see how you can start off testing on the wrong foot. Then we’ll see how asking basic questions like Why, What, How and Where can help you define a sound test strategy in a Continuous Delivery context.
The Deployment Pipeline
Most of the teams nowadays think about Continuous Delivery. Continuous Delivery means automating the release process, from code merge to production release. How do you do that? By using the deployment pipeline pattern. The deployment pipeline models and automates the release process. Here is an example:
In the previous two posts in this series, we’ve seen some examples of long running processes and how to model them. In this article we’ll see where to store the state of a long running process. This is an important topic when talking about long running processes because long running means stateful. We’ll discuss three patterns: storing the state in the domain entity, in the message or in a process instance. To better explain these patterns, we’ll implement subflows from the Order Fulfillment enterprise process.
This is probably the most used approach of the three, although it’s not the best choice in most cases. But it’s overused because it’s simple: you just store the state in the domain entity.
Requirement
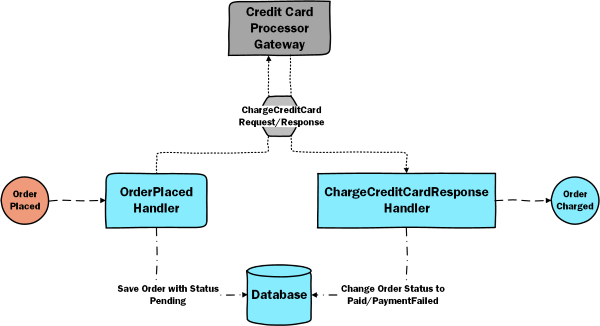
Let’s start with what Finance needs to do when it receives the OrderPlaced event: charge the customer. To do that, it will integrate with a 3rd party payment provider. The long running process in this case handles two message:
the OrderPlaced event – in which case it will send a ChargeCreditCardRequest
the ChargeCreditCardRespone
Implementation
Since we only have two transitions, we could store the state in the Order entity.
Let’s have a look at the code. We’ll use NServiceBus, but the code is readable even if you don’t know NServiceBus or .Net.
In the previous article we’ve seen some examples of long running processes. The purpose of this blog post is to show how to model long running processes by using choreography or orchestration.
Requirement
To better understand the differences between these two approaches, let’s take a long running process and implement it with both. Since we already talked about the Order Fulfillment enterprise process in the last post, let’s use that.
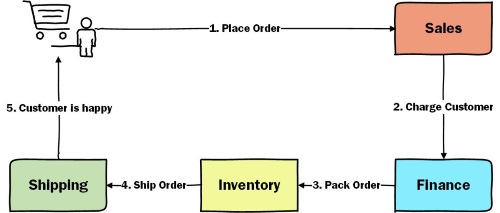
When a customer places an order, we need to approve it, charge the customer’s credit card, pack the order and ship it.
Choreography
Let’s first implement this requirement with choreography. Choreography is all about distributed decision making. When something important happens in a service (or bounded context), the service will publish an event. Other services can subscribe to that event and make decisions based on it.
Most of us are working on distributed systems. Most of us are implementing long running processes. Of course we would like all our long running processes to be:
simple
fast
decoupled
reliable
easy to implement
easy to understand
easy to change
easy to monitor
But this is impossible, so you need to make trade offs. This is why it’s important to have the right tool for the job. But, much of the information out there describes one tool – RPC style integration (e.g. services calling each other over the web, through HTTP). And although this is a good tool, it’s not the best tool in every situation. The purpose of this blog post series is to present some message based patterns that are useful when designing and implementing long running processes.
What is a long running process
First, let’s start with what is a process. A process is a set of operations that are executed in a given order as result of a trigger.
public Task Handle(PlaceOrder message, IMessageHandlerContext context)
{
Data.OrderId = message.OrderId;
Data.TotalValue = message.TotalValue;
Log.Info($"Placing Order with Id {message.OrderId}");
RequestTimeout(context, TimeSpan.FromSeconds(1), new BuyersRemorseTimeout());
return Task.CompletedTask;
}
In this example, the trigger is the PlaceOrder message, and the instructions are in the body of the method.
A long running process is a process that needs to handle more than one message.
{
public Task Handle(PlaceOrder message, IMessageHandlerContext context)
{
Data.OrderId = message.OrderId;
Data.TotalValue = message.TotalValue;
Log.Info($"Placing Order with Id {message.OrderId}");
RequestTimeout(context, TimeSpan.FromSeconds(1), new BuyersRemorseTimeout());
return Task.CompletedTask;
}
public Task Timeout(BuyersRemorseTimeout state, IMessageHandlerContext context)
{
context.Publish<IOrderPlaced>(
o =>
{
o.OrderId = Data.OrderId;
o.TotalValue = Data.TotalValue;
});
MarkAsComplete();
return Task.CompletedTask;
}
}
As you can see, in the handler of the PlaceOrder message, we set some state (the OrderId and TotalValue) and we raise a timeout. In the second handler, when we receive the BuyersRemorseTimeout, we read the state that we saved in the first handler and publish an event.
Long running means that the same process instance will handle multiple messages. That’s it! Long running doesn’t mean long in the sense of time. At least not for people. Such a process could complete in microseconds. Also, a long running process does not need to be actively processing its entire lifetime. Most of the time, it will probably just wait for the next trigger.
Are you working on a distributed system? Microservices, Web APIs, SOA, web server, application server, database server, cache server, load balancer – if these describe components in your system’s design, then the answer is yes. Distributed systems are comprised of many computers that coordinate to achieve a common goal.
More than 20 years ago Peter Deutsch and James Gosling defined the 8 fallacies of distributed computing. These are false assumptions that many developers make about distributed systems. These are usually proven wrong in the long run, leading to hard to fix bugs.
The 8 fallacies are:
The network is reliable
Latency is zero
Bandwidth is infinite
The network is secure
Topology doesn’t change
There is one administrator
Transport cost is zero
The network is homogeneous
Let’s go through each fallacy, discussing the problem and potential solutions.
1. The network is reliable
Problem
Calls over a network will fail.
Most of the systems today make calls to other systems. Are you integrating with 3rd party systems (payment gateways, accounting systems, CRMs)? Are you doing web service calls? What happens if a call fails? If you’re querying data, a simple retry will do. But what happens if you’re sending a command? Let’s take a simple example:
var creditCardProcessor = new CreditCardPaymentService();
creditCardProcessor.Charge(chargeRequest);
What happens if we receive an HTTP timeout exception? If the server did not process the request, then we can retry. But, if it did process the request, we need to make sure we are not double charging the customer. You can do this by making the server idempotent. This means that if you call it 10 times with the same charge request, the customer will be charged only once. If you’re not properly handling these errors, you’re system is nondeterministic. Handling all these cases can get quite complex really fast.
Solutions
So, if calls over a network can fail, what can we do? Well, we could automatically retry. Queuing systems are very good at this. They usually use a pattern called store and forward. They store a message locally, before forwarding it to the recipient. If the recipient is offline, the queuing system will retry sending the message. MSMQ is an example of such a queuing system.
But this change will have a big impact on the design of your system. You are moving from a request/response model to fire and forget. Since you are not waiting for a response anymore, you need to change the user journeys through your system. You cannot just replace each web service call with a queue send.
Conclusion
You might say that networks are more reliable these days – and they are. But stuff happens. Hardware and software can fail – power supplies, routers, failed updates or patches, weak wireless signals, network congestion, rodents or sharks. Yes, sharks: Google is reinforcing undersea data cables with Kevlar after a series of shark bites.
And there’s also the people side. People can start DDOS attacks or they can sabotage physical equipment.
Does this mean that you need to drop your current technology stack and use a messaging system? Probably not! You need to weigh the risk of failure with the investment that you need to make. You can minimize the chance of failure by investing in infrastructure and software. In many cases, failure is an option. But you do need to consider failure when designing distributed systems.