Testing is an important part of building a product right. Continuous Delivery makes that more explicit by building quality in. In this blog post we’ll see how you can start off testing on the wrong foot. Then we’ll see how asking basic questions like Why, What, How and Where can help you define a sound test strategy in a Continuous Delivery context.
The Deployment Pipeline
Most of the teams nowadays think about Continuous Delivery. Continuous Delivery means automating the release process, from code merge to production release. How do you do that? By using the deployment pipeline pattern. The deployment pipeline models and automates the release process. Here is an example:

As a release candidate progresses through the pipeline, your confidence in it increases. But, on the other hand, you get feedback later. Here is a simple example:
- In the CI step you build the solution and run unit tests. You get the results back (feedback) in 3 minutes. You’re 60% confident that you haven’t broken anything.
- You then automatically deploy to a test environment where you run a set of automated tests. This step takes 5 minutes and your confidence level increases to 70%.
- You run the automated regression test suite. This takes 20 minutes and you confidence goes up to 80%.
- The team can then pull the release in an Exploratory environment and do some exploratory testing (if deemed necessary). This might take a couple of hours. Your confidence level increases to 90%.
- The users can then pull the release in the UAT environment and run User Acceptance Testing. This usually takes a couple of days but at the end of a successful UAT you’re 95% certain that you haven’t broken anything.
As you can see, testing is a big part of any deployment pipeline. So how should you define a test strategy in a Continuous Delivery context?
Let’s first see an example of how not to do it.
Don’t try this at home
Meet the Pharaohs
They’re an Agile team working on the next big eCommerce product. They’re in the process of adopting Continuous Delivery practices on their project.
Let’s give some context:
- The product they’re building uses the Microservices architectural style.
- During refinements, the team discuss mostly happy path scenarios. Because of time pressure, they don’t spend too much time discussing complex scenarios.
- Although the team uses BDD, it mostly uses the BDD tooling. The acceptance criteria are very UI oriented, like in the following example. As you can see, this scenario contains more UI terms (navigate, page, click, button, icon) than terms from the business domain (product, add to cart).

- After defining the acceptance criteria, the story gets to the development team. The managers have imposed a unit test coverage target of 90% on the team. No problem: they get there by testing the simplest test cases and making sure that all getters and setters are covered (since this is the complex code that spawns most bugs, right?)
- After finishing the implementation, the devs throw the work over the wall to the testing team.
- There’s a pressure to automate all acceptance criteria. The testing team is spending most of their time on improving their coding skills in order to automate the happy path scenarios. Since the acceptance criteria are defined at the UI level, all tests exercise the entire application through the UI (using a tool like Selenium).
- Because it takes time to automate, the team doesn’t have enough time to think about more complex scenarios or run Exploratory testing.
Outcome
As you can see, the Pharaohs are not in a good place:
- They have a lot of unit tests that test really simple logic. These tests will never fail. This means they’re useless.
- Of course, not all logic is simple. There is a god class that attracts most of the complex behavior in the system. But, since god classes are notoriously hard to test, it’s not tested. So the most complex piece of code falls in the 10% of code that’s not covered by tests.
- Because the devs and testers don’t collaborate, they are duplicating test cases.
- The UI test suite takes a long time to run and it’s flaky. This means that it might pass or fail randomly, without any change to the code or the infrastructure.
- Since the team spends most of their testing budget on learning how to automate, they don’t spend enough time on exploratory. So most bugs are found in UAT or, even worse, in Production.
As you can see, this team suffers from the 7 deadly sins of test automation. They don’t reap the benefits of Continuous Delivery. Most of the valuable feedback comes late in the process, from UAT and Production. So what can the Pharaohs do?
Enter the Pyramid
They ask for advice and someone tells them they’re doing it all wrong. They are not following the test pyramid:
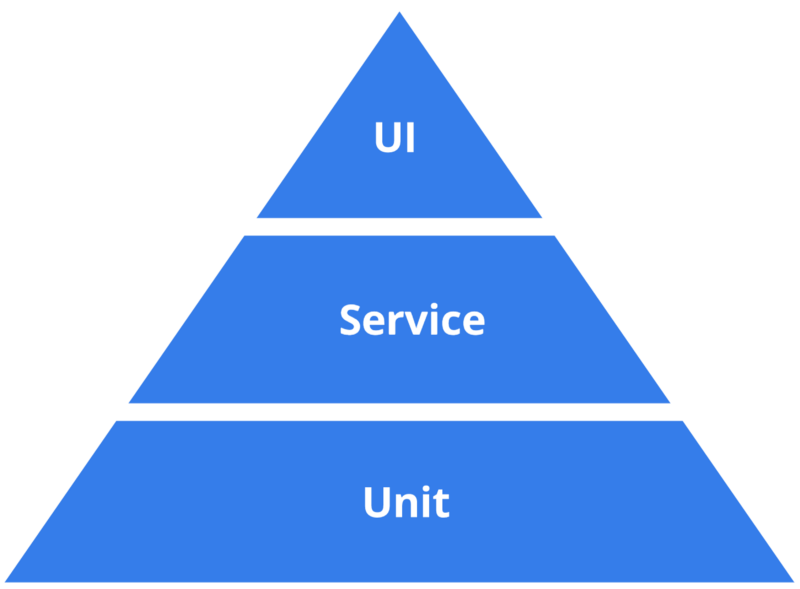
The Test Pyramid is a model that tells you how many tests to write at each layer. Since unit tests are the fastest, you should have a lot of them. At the next layer you should have a smaller number of Integration/Service tests that check how different components interact. UI tests sit at the top of the pyramid. These tests are flaky and take a long time to run, so you should have fewer test cases implemented at this level.
So the Pharaohs now see that they have too many UI tests. The devs and testers start to collaborate and move most of the UI tests at the Integration layer (and maybe some at unit level). This helps them get rid of the long and flaky UI test suite and it removes most of the duplicated test cases. Unfortunately, they still have useless unit tests, untested god class and bugs are still found in UAT and production.
So the pyramid didn’t fix all the problems. Why?
Context is King
The problem is that the test pyramid doesn’t care about the context. John Ferguson Smart reminds us that the Test Pyramid is a model. And, as George Box reminds us:
All models are wrong; some models are useful .
George Box
The test pyramid is wrong, but it is useful is some contexts.
Monolithic Architecture
The concept first appeared in 2003. At that time most systems used a monolithic architecture. For this type of architecture, the Test Pyramid might be the correct starting point. But computing resources have become faster and more accessible and the tools have gotten better. So is the Test Pyramid the right approach in all cases? Of course not.
CRUD Applications
As Todd Gardner says, if you’re working on a CRUD application that relies on a framework to load and store data in the Database, the Testing Pyramid won’t help you. You don’t have complex logic to unit test. But you do integrate with a database and you might want to check that your SQL queries are correct. So, in this case, maybe the Inverted Test Pyramid is the right approach.

Service-based Architecture
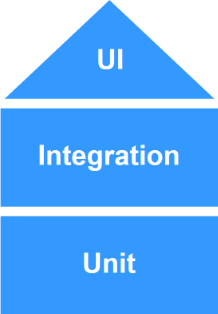
What if you use a service-based architecture. You have 5 big services. In this case, some of the complexity has moved from inside the services to the interaction between them.
This means that some of the risk has moved from inside the units to the interaction between them. In this case maybe it makes sense to have the same number of unit and service tests. You’re building a test house:
Serverless Architecture
In a Serverless architecture you might have tens or hundreds of functions. Each function is quite simple, but the complexity has moved at the integration level. Is the function trigger configured correctly? Does it have permission to read from the Database? For these reason, people are recommending the Test Honeycomb approach for testing serverless architectures.
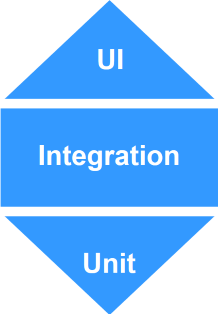
So if the test pyramid is not the answer, where do you start? Well, the test pyramid only answers the How question. You should aim to answer Why, What and Where too.
Why
Identifying Risk
It’s only normal that you should start with why. Why do I test? And I think it has a lot to do with managing risk. As James Coplien puts it:
Good testing, again, is based on careful thought and on basic principles of risk management.; (…) without rudimentary skills in this area, then you are likely to do a lot of useless tests.
James O Coplien
So the first thing you need to do is to identify the risk profile of the product you are building. Here are some of the risk types that you should consider:
- Functional risk – if you’re dealing with complex business behavior or complicated algorithms. This is the kind of behavior that you should spend time unit testing.
- Integration risk – if you’re integrating with a lot of services and 3rd party applications. This is the type of risk that can be managed by integration tests. Also, if there’s a partnership relationship between the service producer and consumer, then maybe the consumer can write some contract tests that run in the producer’s pipeline for faster feedback.
- Configuration risk. Maybe you’ve bought a 3rd party application and you’ve configured it to suite your needs. In this case you need to reduce the risk that it’s not configured properly.
- Orchestration risk – if you have a component that orchestrates other components/services. This type of component should be unit/component tested.
- API Design risk. You’re working on an open source library or an open API. In this case, you need to make sure that the API is usable, so you could drive the design with tests.
- You’re dealing with some hard to achieve Quality Attributes (e.g. Scalability, Performance, Availability). In this case spend time testing for these quality attributes.
- Refactoring risk – you need to perform a large refactoring on the app and you are not covered. In this case you could implement some characterization tests or Golden Master tests.
- Market risk – let’s not forget about this one. There is no point in building the product right if it’s not the right product. So in this case maybe you should invest in A/B testing, canary releasing and real user monitoring.
- Miscommunication risk – if the business/client is in one organization and the development team is in another (for example service companies), there’s a risk that there will be miscommunication between these two sides. In this case maybe it makes sense to invest in living documentation. This can help build a shared understanding. If we’re talking about business documentation, then invest in BDD and automate your scenarios with tools like Cucumber and SpecFlow. If you’re working on an API, invest in technical documentation. This can take the form of a test suite, a sample application and/or a wiki.
So, as Todd Gardner puts it:
We should think scales instead of pyramids when it comes to software development testing.
Todd Gardner
By thinking scales, you can make better decisions. For example, the team has decided that the highest risk is that there isn’t a product/market fit. So they focus on removing that risk by trying to get the product in the hands of the users as soon as possible. If there’s market demand, then the risk moves elsewhere. Let’s say that the highest risk is now functional. The team then decides to spend more time unit testing. This is what Liz Keogh and Dan North call Spike & Stabilize.
Using Historical Data
The best way to make a decision is to base it on facts. This is why it’s a good idea to look at the areas of code that generate most bugs when identifying risk. Because, if that code generated bugs in the past, it’s likely that it will generate bugs in the future.
The good news is that there are practices and tools that can help you with that by looking at the source code history. It can be quite simple: if you use Smart Commits and add the issue tracker Id in the commit message, then you can use this information to pinpoint bug magnets. If in almost all commits to a file you reference bug IDs, then that file is very likely to generate bugs. Adam Tornhill‘s books, Your Code as a Crime Scene and Software Design X-Rays describe the techniques, so have a look if you’re interested in finding out how you can extract new knowledge and insight from your source code’s history.
Acceptance vs. Regression
Another question to ask is: are you trying to prove to someone (e.g. the Product Owner) that the software works as discussed? If so, then this is an Acceptance Test. If you’re trying to ensure that this doesn’t break in the future, it’s a Regression Test.
What
Now that you’ve identified the risk that you’re trying to mitigate, you can move to What. You can now look at the system and ask What should I test?
Let’s take an example of a system – an eCommerce product – that uses SOA as a top-level architecture. So a System is made up of Services. Services are made up of Components. Components are made up of Classes. A Class can have many methods. And of course it connects to Databases, Queues and 3rd party web APIs.
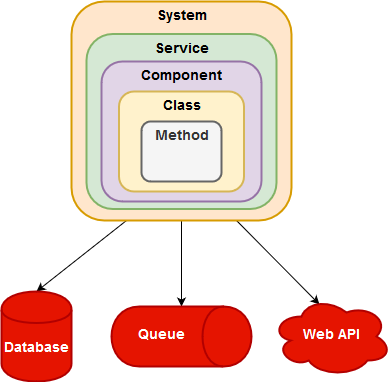
- System – If you want to make sure that everything is setup and a user of the product can do the most important actions: e.g. see a product, select it, buy something, then test at the system level.
- Service – If you want to make sure the shipping business capability works, then test the shipping service.
- Component – If you want to make sure that the discount is computed correctly – then test the Discount component.
- Class – If you want to make sure that the invoice lines are correctly displayed – then test the InvoiceLinePrinter class.
- Method – If you want to make sure that the amount is formatted correctly with different parameters and that is in a static method, then test that method.
- Integration – If you want to make sure that you can connect to the Oracle database and the SQL query is correct, test the repository class with the database.
The purpose of this step is to pinpoint the risk to the smallest What. Of course you could only test at the system level, but then you’ll have very slow feedback.
How
You’ve answered Why and What and you’ve identified a particular scenario that you should test. The next question is How should I test it? After answering this question, you should know what type of tests to implement (e.g. unit tests, integration tests, etc.). Here are some questions that might point you in the right direction:
- First, check again if you need to automate this scenario. If it’s not a risky area and you want to get the feature quickly to production, maybe it makes sense not to automate it now.
- If you do need to automate it, can it be fast and reliable? Can it run in process without sacrificing confidence? At this point you can think again if you can move it to a level below. For example, instead of implementing an HTTP API test, maybe you can implement a component and an integration test.
- Do you need to keep the test around? The cost of a test is not fully paid after implementing it. Many times the cost of running and maintaining the test is larger. Some tests should be thrown away after running them. For example, you might implement some coarse grained scaffolding tests before a big refactoring effort. After the refactoring is done and you’ve implemented more focused tests, you can throw away the scaffolding tests.
So, after some careful thought you can decide how to test: unit, integration, integrated, HTTP API, End-to-end, manual, test in production.
Make sure that everyone on the team has the same definitions for the different test types. Different people mean different things when they say unit test or integration test. This is why it’s important to have a common understanding of the different test types inside the team.
Another tip is to always look at the bigger picture when you decide on how to test. For example, you could define a test recipe for each story/feature. The idea is pretty simple: before starting to work on a feature, some members of the team (developers, testers, architects) get together and decide at what level should they test the different acceptance criteria. On a previous team we did this during the planning session. It was quite effective in increasing collaboration between devs and testers, building a shared understanding and keeping the test pack lean.
Where
Now we’re down to where: Where should I run my test? Here are a few tips:
- Typically, each test type (identified in the How step) has its own step in the pipeline.
- As the tests get slower, they are ran later in the pipeline.
- Many times it’s useful to move a subset of slower tests earlier in the pipeline for faster feedback. For example, if there are a couple of tests that always seem to find bugs, it makes sense to move them earlier. Another good example are tests for quality attributes, like performance tests. These tests can take a long time to run, so they run later in the pipeline. But, if performance of the checkout process is very important and it degrades easily, it makes sense to run just that performance test earlier in the pipeline.
Here is an example of mapping test types to steps in the Deployment Pipeline:
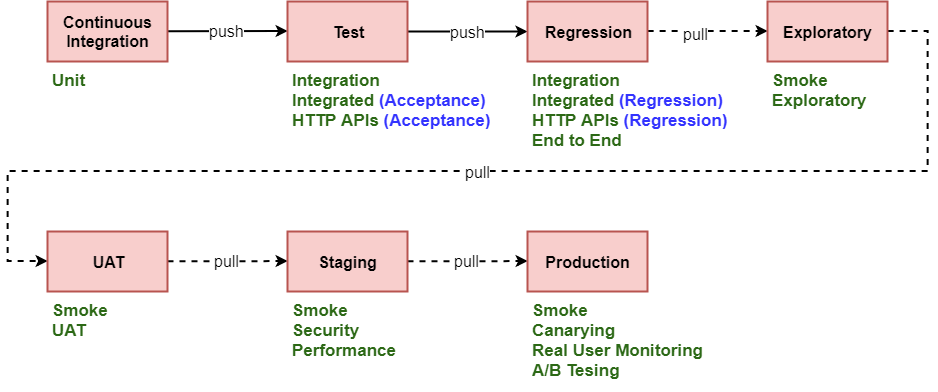
A couple of notes on the setup above:
- The Test step runs only the Integrated and HTTP API tests that are also used for Acceptance. These are tests for functionality that the team is implementing (or changing) in the current iteration. These have a higher likelihood of failing, as the production code is updated. This is why we want to run them earlier in the pipeline: to get feedback early.
- We run Smoke tests in the Exploratory, UAT, Staging and Production stages. This is a relatively fast test suite that makes sure that the main flows through the application are still working.
The key point at this step is to balance feedback and confidence when choosing where to run the test. A tip that can help you in achieving this balance is to define a run time budget per test stage. For example, the Smoke Test pack should run in under 5 minutes. If it takes more then that, the step fails and the pipeline stops. This way, you avoid slowly but steadily increasing the run time of a test pack to the point that it becomes a bottleneck for the team.
I’ve been there myself and have seen a 10 minutes test pack growing to 60 minutes. It’s like in the boiling frog fable – you only notice it when it’s already late and much harder to fix the problem. You can avoid this situation by setting a budget. And, if when you’ve exceeded the budget, you decide to extend it, at least you’ve weighted the pros and cons and made a conscious decision.
Who
You might be wondering why I skipped the Who question: Who should define, implement and manage the test code? The answer is pretty simple: quality is everyone’s responsibility. Test code should be treated as a first class citizen and should be held to the same quality standards as production code.
Defining the test cases requires a different mindset than implementing the code. It’s better that the test cases are not defined by the same person that implemented the feature.
Implementing good automated tests requires serious development skills. This is why, if there are people on the team that are just learning to code (for example testers that are new to test automation), it’s a good idea to make sure that the team is giving them the right amount of support to skill up. This should be done through pairing, code review, knowledge sharing sessions. Remember that the entire team owns the codebase. Don’t fall into the split ownership trap, in which production code is owned by the devs and test code is owned by the testers. This hinders knowledge sharing, introduces test case duplication and can lead to a drop in test code quality.
Developers and testers are not the only ones that care about the quality. Ideally, the Product Owner should define most of the acceptance criteria. She is the one that has the best understanding of the problem domain and its essential complexity. So she should be a major contributor when writing acceptance criteria. The Three Amigos can play an important role in making sure that you see a feature from all perspectives: business, development and testing.
Conclusion
To sum this up:
- Don’t trust the pyramid. The Test Pyramid is a model. This means that it’s useful only in some contexts. This is, in part, because it’s only considering how you test. This is not enough. Always consider the context you’re in.
- Think about Why: what’s the risk profile of the product? The testing that you do should mitigate that risk.
- Think about What: what’s the smallest part of the application that contains the risk?
- Think about How: how should you test it? At what level?
- Think about Where: where in the deployment pipeline should you run the test for the best balance of feedback and confidence?